Conceptos de Despliegue¶
Al desplegar una aplicación FastAPI, o en realidad, cualquier tipo de API web, hay varios conceptos que probablemente te importan, y usándolos puedes encontrar la forma más apropiada de desplegar tu aplicación.
Algunos de los conceptos importantes son:
- Seguridad - HTTPS
- Ejecución al inicio
- Reinicios
- Replicación (el número de procesos en ejecución)
- Memoria
- Pasos previos antes de iniciar
Veremos cómo afectarían a los despliegues.
Al final, el objetivo final es poder atender a los clientes de tu API de una forma que sea segura, para evitar interrupciones, y usar los recursos de cómputo (por ejemplo servidores remotos/máquinas virtuales) de la manera más eficiente posible. 🚀
Te contaré un poco más sobre estos conceptos aquí, y eso con suerte te dará la intuición que necesitarías para decidir cómo desplegar tu API en entornos muy diferentes, posiblemente incluso en futuros que aún no existen.
Al considerar estos conceptos, podrás evaluar y diseñar la mejor forma de desplegar tus propias APIs.
En los próximos capítulos, te daré más recetas concretas para desplegar aplicaciones FastAPI.
Pero por ahora, revisemos estas importantes ideas conceptuales. Estos conceptos también aplican a cualquier otro tipo de API web. 💡
Seguridad - HTTPS¶
En el capítulo anterior sobre HTTPS aprendimos cómo HTTPS proporciona cifrado para tu API.
También vimos que HTTPS normalmente es proporcionado por un componente externo a tu servidor de aplicaciones, un TLS Termination Proxy.
Y tiene que haber algo encargado de renovar los certificados HTTPS, podría ser el mismo componente o podría ser algo diferente.
Herramientas de Ejemplo para HTTPS¶
Algunas de las herramientas que puedes usar como TLS Termination Proxy son:
- Traefik
- Maneja automáticamente las renovaciones de certificados ✨
- Caddy
- Maneja automáticamente las renovaciones de certificados ✨
- Nginx
- Con un componente externo como Certbot para la renovación de certificados
- HAProxy
- Con un componente externo como Certbot para la renovación de certificados
- Kubernetes with an Ingress Controller like Nginx
- Con un componente externo como cert-manager para la renovación de certificados
- Manejado internamente por un proveedor de nube como parte de sus servicios (lee más abajo 👇)
Otra opción es que podrías usar un servicio en la nube que haga más del trabajo incluyendo configurar HTTPS. Podría tener algunas restricciones o cobrarte más, etc. Pero en ese caso, no tendrías que configurar un TLS Termination Proxy tú mismo.
Te mostraré algunos ejemplos concretos en los próximos capítulos.
Luego los siguientes conceptos a considerar tienen que ver con el programa que ejecuta tu API (por ejemplo, Uvicorn).
Programa y Proceso¶
Hablaremos mucho sobre el "proceso" en ejecución, así que es útil tener claridad sobre qué significa y cuál es la diferencia con la palabra "programa".
Qué es un Programa¶
La palabra programa se usa comúnmente para describir muchas cosas:
- El código que escribes, los archivos de Python.
- El archivo que puede ser ejecutado por el sistema operativo, por ejemplo:
python,python.exeouvicorn. - Un programa particular mientras está en ejecución en el sistema operativo, usando la CPU y almacenando cosas en memoria. Esto también se llama proceso.
Qué es un Proceso¶
La palabra proceso se usa normalmente de una manera más específica, refiriéndose solo a la cosa que está en ejecución en el sistema operativo (como en el último punto anterior):
- A particular program while it is running on the operating system.
- Esto no se refiere al archivo ni al código, se refiere específicamente a la cosa que está siendo ejecutada y gestionada por el sistema operativo.
- Cualquier programa, cualquier código, solo puede hacer cosas cuando está siendo ejecutado. Es decir, cuando hay un proceso en ejecución.
- El proceso puede ser terminado (o "matado") por ti o por el sistema operativo. En ese punto, deja de ejecutarse y ya no puede hacer cosas.
- Cada aplicación que tienes en ejecución en tu computadora tiene algún proceso detrás, cada programa en ejecución, cada ventana, etc. Y normalmente hay muchos procesos ejecutándose al mismo tiempo mientras una computadora está encendida.
- Puede haber múltiples procesos del mismo programa ejecutándose al mismo tiempo.
Si revisas el "administrador de tareas" o el "monitor del sistema" (o herramientas similares) en tu sistema operativo, podrás ver muchos de esos procesos en ejecución.
Y, por ejemplo, probablemente verás que hay múltiples procesos ejecutando el mismo programa de navegador (Firefox, Chrome, Edge, etc). Normalmente ejecutan un proceso por pestaña, más algunos otros procesos adicionales.
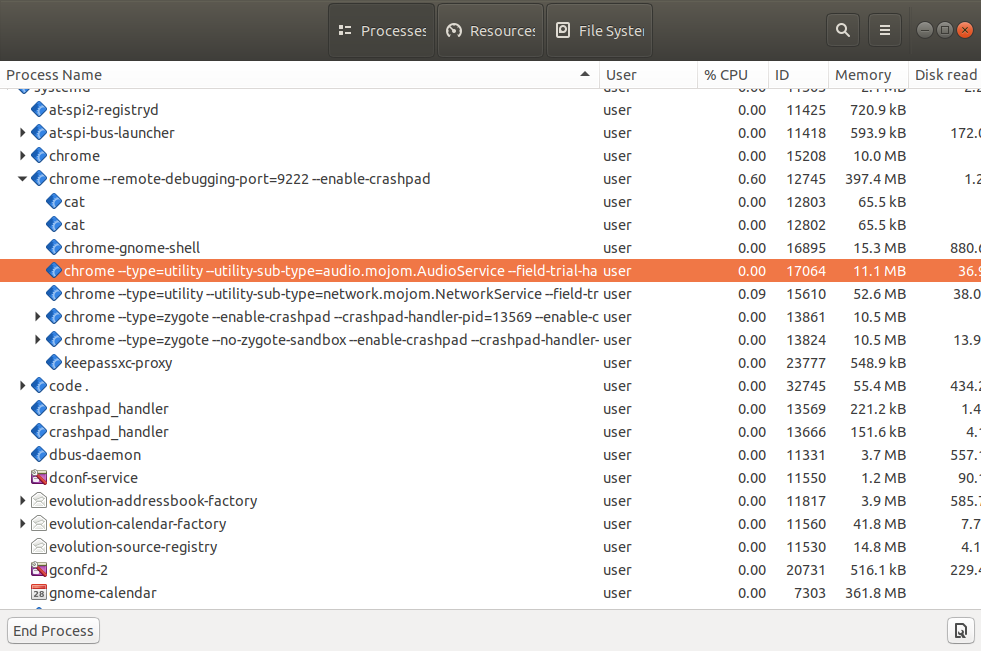
Ahora que sabemos la diferencia entre los términos proceso y programa, sigamos hablando sobre despliegues.
Ejecución al Inicio¶
En la mayoría de los casos, cuando creas una API web, quieres que esté siempre en ejecución, sin interrupciones, para que tus clientes siempre puedan acceder a ella. Esto, por supuesto, a menos que tengas una razón específica por la que quieras que se ejecute solo en ciertas situaciones, pero la mayoría del tiempo quieres que esté constantemente en ejecución y disponible.
En un Servidor Remoto¶
Cuando configuras un servidor remoto (un servidor en la nube, una máquina virtual, etc.) lo más simple que puedes hacer es usar fastapi run (que usa Uvicorn) o algo similar, manualmente, de la misma manera que lo haces cuando desarrollas localmente.
Y funcionará y será útil durante el desarrollo.
Pero si se pierde tu conexión al servidor, el proceso en ejecución probablemente morirá.
Y si el servidor se reinicia (por ejemplo después de actualizaciones o migraciones del proveedor de nube) probablemente no te darás cuenta. Y debido a eso, ni siquiera sabrás que tienes que reiniciar el proceso manualmente. Así que, tu API simplemente se quedará muerta. 😱
Ejecutar Automáticamente al Inicio¶
En general, probablemente querrás que el programa del servidor (por ejemplo, Uvicorn) se inicie automáticamente al arrancar el servidor, y sin necesitar ninguna intervención humana, para tener un proceso siempre en ejecución con tu API (por ejemplo, Uvicorn ejecutando tu aplicación FastAPI).
Programa Separado¶
Para lograr esto, normalmente tendrás un programa separado que se asegure de que tu aplicación se ejecute al inicio. Y en muchos casos, también se aseguraría de que otros componentes o aplicaciones también se ejecuten, por ejemplo, una base de datos.
Herramientas de Ejemplo para Ejecutar al Inicio¶
Algunos ejemplos de las herramientas que pueden hacer este trabajo son:
- Docker
- Kubernetes
- Docker Compose
- Docker en Modo Swarm
- Systemd
- Supervisor
- Manejado internamente por un proveedor de nube como parte de sus servicios
- Otros...
Te daré más ejemplos concretos en los próximos capítulos.
Reinicios¶
De manera similar a asegurarte de que tu aplicación se ejecute al inicio, probablemente también quieras asegurarte de que se reinicie después de fallos.
Cometemos Errores¶
Nosotros, como humanos, cometemos errores todo el tiempo. El software casi siempre tiene bugs ocultos en diferentes lugares. 🐛
Y nosotros como desarrolladores seguimos mejorando el código a medida que encontramos esos bugs y a medida que implementamos nuevas funcionalidades (posiblemente añadiendo nuevos bugs también 😅).
Errores Pequeños Manejados Automáticamente¶
Al construir APIs web con FastAPI, si hay un error en nuestro código, FastAPI normalmente lo contendrá a la única petición que provocó el error. 🛡
El cliente recibirá un 500 Internal Server Error para esa petición, pero la aplicación seguirá funcionando para las siguientes peticiones en lugar de simplemente caerse por completo.
Errores Mayores - Caídas¶
Sin embargo, puede haber casos donde escribimos código que hace caer toda la aplicación haciendo que Uvicorn y Python se caigan. 💥
Y aún así, probablemente no querrás que la aplicación se quede muerta porque hubo un error en un lugar, probablemente quieras que siga en ejecución al menos para las path operations que no están rotas.
Reiniciar Después de una Caída¶
Pero en esos casos con errores realmente graves que hacen caer el proceso en ejecución, querrías un componente externo que se encargue de reiniciar el proceso, al menos un par de veces...
Consejo
...Aunque si toda la aplicación simplemente se cae inmediatamente probablemente no tenga sentido seguir reiniciándola para siempre. Pero en esos casos, probablemente te darás cuenta durante el desarrollo, o al menos justo después del despliegue.
Así que centrémonos en los casos principales, donde podría caerse por completo en algunos casos particulares en el futuro, y aún tiene sentido reiniciarla.
Probablemente querrás que la cosa encargada de reiniciar tu aplicación sea un componente externo, porque para ese punto, la misma aplicación con Uvicorn y Python ya se ha caído, así que no hay nada en el mismo código de la misma app que pueda hacer algo al respecto.
Herramientas de Ejemplo para Reiniciar Automáticamente¶
En la mayoría de los casos, la misma herramienta que se usa para ejecutar el programa al inicio también se usa para manejar los reinicios automáticos.
Por ejemplo, esto podría ser manejado por:
- Docker
- Kubernetes
- Docker Compose
- Docker en Modo Swarm
- Systemd
- Supervisor
- Manejado internamente por un proveedor de nube como parte de sus servicios
- Otros...
Replicación - Procesos y Memoria¶
Con una aplicación FastAPI, usando un programa de servidor como el comando fastapi que ejecuta Uvicorn, ejecutarlo una vez en un proceso puede atender a múltiples clientes concurrentemente.
Pero en muchos casos, querrás ejecutar varios procesos worker al mismo tiempo.
Múltiples Procesos - Workers¶
Si tienes más clientes de los que un solo proceso puede manejar (por ejemplo si la máquina virtual no es muy grande) y tienes múltiples núcleos en la CPU del servidor, entonces podrías tener múltiples procesos ejecutándose con la misma aplicación al mismo tiempo, y distribuir todas las peticiones entre ellos.
Cuando ejecutas múltiples procesos del mismo programa de API, se les llama comúnmente workers.
Procesos Worker y Puertos¶
¿Recuerdas de la documentación Sobre HTTPS que solo un proceso puede estar escuchando en una combinación de puerto y dirección IP en un servidor?
Esto sigue siendo cierto.
Entonces, para poder tener múltiples procesos al mismo tiempo, tiene que haber un único proceso escuchando en un puerto que luego transmita la comunicación a cada proceso worker de alguna manera.
Memoria por Proceso¶
Ahora, cuando el programa carga cosas en memoria, por ejemplo, un modelo de machine learning en una variable, o los contenidos de un archivo grande en una variable, todo eso consume un poco de la memoria (RAM) del servidor.
Y múltiples procesos normalmente no comparten ninguna memoria. Esto significa que cada proceso en ejecución tiene sus propias cosas, variables y memoria. Y si estás consumiendo una gran cantidad de memoria en tu código, cada proceso consumirá una cantidad equivalente de memoria.
Memoria del Servidor¶
Por ejemplo, si tu código carga un modelo de Machine Learning con 1 GB de tamaño, cuando ejecutas un proceso con tu API, consumirá al menos 1 GB de RAM. Y si inicias 4 procesos (4 workers), cada uno consumirá 1 GB de RAM. Así que en total, tu API consumirá 4 GB de RAM.
Y si tu servidor remoto o máquina virtual solo tiene 3 GB de RAM, intentar cargar más de 4 GB de RAM causará problemas. 🚨
Múltiples Procesos - Un Ejemplo¶
En este ejemplo, hay un Proceso Manager que inicia y controla dos Procesos Worker.
Este Proceso Manager probablemente sería el que escucha en el puerto en la IP. Y transmitiría toda la comunicación a los procesos worker.
Esos procesos worker serían los que ejecutan tu aplicación, realizarían los cálculos principales para recibir una petición y devolver una respuesta, y cargarían en RAM todo lo que pongas en variables.

Y por supuesto, la misma máquina probablemente tendría otros procesos en ejecución también, aparte de tu aplicación.
Un detalle interesante es que el porcentaje de CPU usada por cada proceso puede variar mucho con el tiempo, pero la memoria (RAM) normalmente se mantiene más o menos estable.
Si tienes una API que hace una cantidad comparable de cálculos cada vez y tienes muchos clientes, entonces la utilización de CPU probablemente también sea estable (en lugar de subir y bajar constantemente de forma rápida).
Ejemplos de Herramientas y Estrategias de Replicación¶
Puede haber varios enfoques para lograr esto, y te contaré más sobre estrategias específicas en los próximos capítulos, por ejemplo al hablar sobre Docker y contenedores.
La principal restricción a considerar es que tiene que haber un componente único manejando el puerto en la IP pública. Y luego tiene que tener una forma de transmitir la comunicación a los procesos/workers replicados.
Aquí hay algunas combinaciones y estrategias posibles:
- Uvicorn with
--workers- Un gestor de procesos de Uvicorn escucharía en la IP y el puerto, e iniciaría múltiples procesos worker de Uvicorn.
- Kubernetes and other distributed container systems
- Algo en la capa de Kubernetes escucharía en la IP y el puerto. La replicación sería teniendo múltiples contenedores, cada uno con un proceso de Uvicorn en ejecución.
- Cloud services that handle this for you
- El servicio en la nube probablemente maneje la replicación por ti. Posiblemente te permitiría definir un proceso a ejecutar, o una imagen de contenedor a usar, en cualquier caso, lo más probable es que sea un único proceso de Uvicorn, y el servicio en la nube se encargaría de replicarlo.
Consejo
No te preocupes si algunos de estos elementos sobre contenedores, Docker o Kubernetes no tienen mucho sentido todavía.
Te contaré más sobre imágenes de contenedores, Docker, Kubernetes, etc. en un capítulo futuro: FastAPI en Contenedores - Docker.
Pasos Previos Antes de Iniciar¶
Hay muchos casos donde quieres realizar algunos pasos antes de iniciar tu aplicación.
Por ejemplo, podrías querer ejecutar migraciones de base de datos.
Pero en la mayoría de los casos, querrás realizar estos pasos solo una vez.
Así que, querrás tener un único proceso para realizar esos pasos previos, antes de iniciar la aplicación.
Y tendrás que asegurarte de que sea un único proceso ejecutando esos pasos previos incluso si después, inicias múltiples procesos (múltiples workers) para la aplicación misma. Si esos pasos fueran ejecutados por múltiples procesos, duplicarían el trabajo al ejecutarlo en paralelo, y si los pasos fueran algo delicado como una migración de base de datos, podrían causar conflictos entre sí.
Por supuesto, hay algunos casos donde no hay problema en ejecutar los pasos previos múltiples veces, en ese caso, es mucho más fácil de manejar.
Consejo
Además, ten en cuenta que dependiendo de tu configuración, en algunos casos podrías ni siquiera necesitar pasos previos antes de iniciar tu aplicación.
En ese caso, no tendrías que preocuparte por nada de esto. 🤷
Ejemplos de Estrategias de Pasos Previos¶
Esto dependerá en gran medida de la forma en que despliegues tu sistema, y probablemente estaría conectado a la forma en que inicias programas, manejas reinicios, etc.
Aquí hay algunas ideas posibles:
- Un "Init Container" en Kubernetes que se ejecuta antes del contenedor de tu app
- A bash script that runs the previous steps and then starts your application
- Aún necesitarías una forma de iniciar/reiniciar ese script de bash, detectar errores, etc.
Consejo
Te daré ejemplos más concretos para hacer esto con contenedores en un capítulo futuro: FastAPI en Contenedores - Docker.
Utilización de Recursos¶
Tu(s) servidor(es) es (son) un recurso, puedes consumir o utilizar, con tus programas, el tiempo de cómputo en las CPUs y la memoria RAM disponible.
¿Cuánto de los recursos del sistema quieres estar consumiendo/utilizando? Puede ser fácil pensar "no mucho", pero en realidad, probablemente querrás consumir tanto como sea posible sin caerse.
Si estás pagando por 3 servidores pero estás usando solo una pequeña parte de su RAM y CPU, probablemente estás desperdiciando dinero 💸, y probablemente desperdiciando energía eléctrica del servidor 🌎, etc.
En ese caso, podría ser mejor tener solo 2 servidores y usar un mayor porcentaje de sus recursos (CPU, memoria, disco, ancho de banda de red, etc).
Por otro lado, si tienes 2 servidores y estás usando el 100% de su CPU y RAM, en algún momento un proceso pedirá más memoria, y el servidor tendrá que usar el disco como "memoria" (lo cual puede ser miles de veces más lento), o incluso caerse. O un proceso podría necesitar hacer algún cálculo y tendría que esperar hasta que la CPU esté libre de nuevo.
En este caso, sería mejor conseguir un servidor adicional y ejecutar algunos procesos en él para que todos tengan suficiente RAM y tiempo de CPU.
También existe la posibilidad de que por alguna razón tengas un pico de uso de tu API. Quizás se hizo viral, o quizás otros servicios o bots empezaron a usarla. Y podrías querer tener recursos adicionales para estar seguro en esos casos.
Podrías poner un número arbitrario como objetivo, por ejemplo, algo entre 50% y 90% de utilización de recursos. El punto es que esas son probablemente las principales cosas que querrás medir y usar para ajustar tus despliegues.
Puedes usar herramientas simples como htop para ver la CPU y RAM usadas en tu servidor o la cantidad usada por cada proceso. O puedes usar herramientas de monitoreo más complejas, que pueden estar distribuidas entre servidores, etc.
Resumen¶
Has estado leyendo aquí algunos de los conceptos principales que probablemente necesitarás tener en cuenta al decidir cómo desplegar tu aplicación:
- Seguridad - HTTPS
- Ejecución al inicio
- Reinicios
- Replicación (el número de procesos en ejecución)
- Memoria
- Pasos previos antes de iniciar
Entender estas ideas y cómo aplicarlas debería darte la intuición necesaria para tomar cualquier decisión al configurar y ajustar tus despliegues. 🤓
En las próximas secciones, te daré ejemplos más concretos de posibles estrategias que puedes seguir. 🚀